Extractive Summarization in Dialogue with GCNN
X-INF554 Kaggle Data Challenge
Data challenge held by LIX, École polytechnique, as the final project of course INF554 - Apprentissage Automatique et Profond (2023-2024).
Topic: Extractive Summarization with Discourse Graphs
Team: GWG
Members: Chenwei WAN (DATAAI), Xianjin GONG (IGD), Mengfei GAO (IGD)
Our final ranking: 5/65
Project Overview
Data set – 137 dialogues from role-playing conversations between 4 participants
- A sequence of utterances
- Min number of utterances: 126 (ES2005a)
- Max number of utterances: 2160 (TS3005d)
- A discourse graph (16 types of relations)
- Max length of edges: 20 (ES2008c)
- Unbalanced data set (positive : negative = 13,292 : 59,331)
Mission – Extractive Summarization: Binary classification on utterances based on context information
Evaluation Metric – Discrete F1 Score
Contribution: Data Visualization
Why visualization is needed ?
- Raw data separated in multiple files (utterances, discourse connections, and importance labels)
- Difficult to find context information for a node for analysis (when its prediction is wrong)
- Difficult to locate one-ring neighbors for a node when the link is long
Implementation
- For each node
- Red star shape – Important nodes
- Dark blue round shape – Non-important nodes
- Number – Utterance index in the corresponding dialogue file
- For each connection
- Different colors to show types of connections (undirected here because the index provides the direction info)
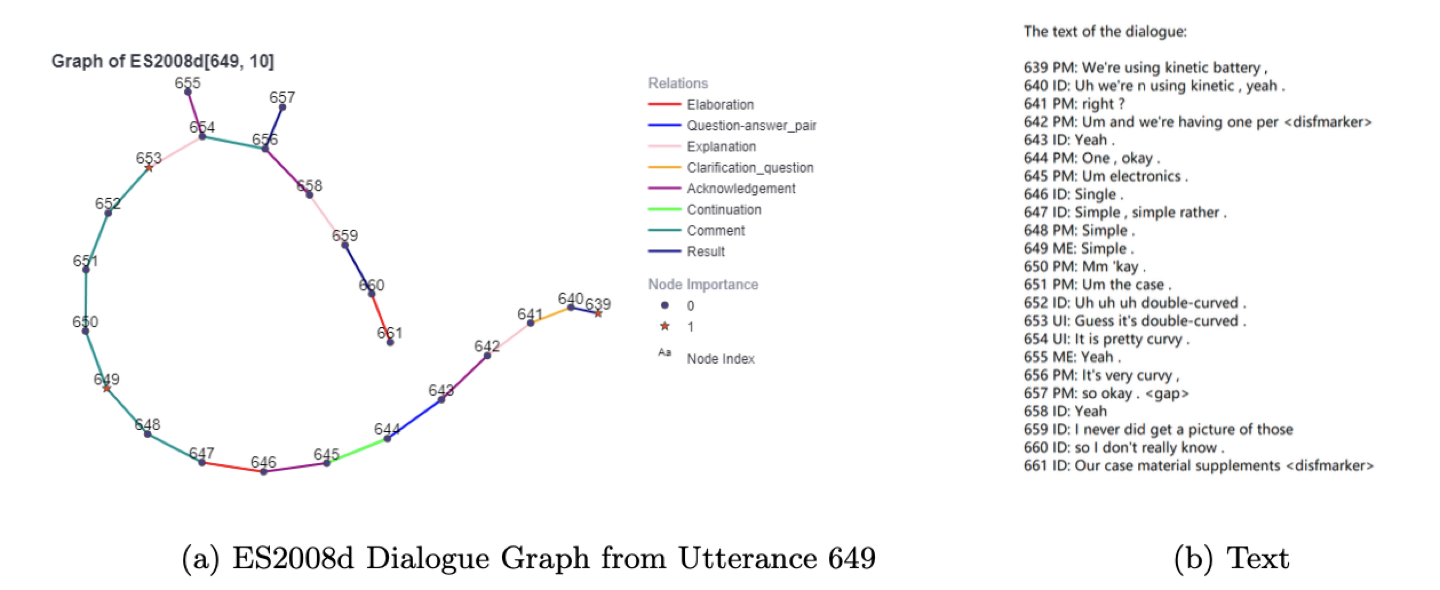
- Different colors to show types of connections (undirected here because the index provides the direction info)